Cogent Raises $42M Series A - Read more here
Jan 9, 2026
Your Agent Is Fine. Your Process Isn't.
The Unglamorous Work That Makes AI Agents Productive

Anirudh Ravula, Head of AI

Introduction
The conversation around AI agents in software development has split into two camps. One side has OpenAI publishing Harness engineering, Sora for Android built in 28 days , Simon Willison documenting StrongDM's Dark Factory approach where no human even looks at the code. The other has METR showing experienced developers were 19% slower with agents. Both are probably right — just measuring different things. But neither asks the question we kept running into: is the process around the agent set up for the agent to succeed? The loudest voices say the answer is more autonomy — remove humans from the loop, let agents handle everything. We built one set of tools that either a developer or an agent could operate — same CLI, same workflow.
The bet was that the path to autonomous agents runs through evolving your process, not around it.
We've been firmly in the bullish camp since the start. Cogent is a small team building a security platform for exposure management. We've used AI agents for development from day one — there was no "before AI" workflow to compare against. Agents have been writing production code here since the beginning. This post pattern-matches against what worked, what didn't, and what broke quietly enough that we almost missed it.
For most of that time, it worked well. Agents handled implementation, wrote tests, moved through tickets. The team shipped insanely fast relative to our size.
Then, around four months ago, things started to slip. Not dramatically — nothing broke in an obvious way. Agents would produce code that wasn't broken, just off — solving the literal task while missing the intent. Rework crept up. We were still shipping PRs at the same rate, but the real cost was hiding downstream — bugs surfacing weeks later, rework cycles that didn't get attributed back to the original change.
We realized we had scaled our use of AI without evolving the process that made AI useful. The agent was fine. Our process wasn't.
The Productivity Curve Nobody Talks About
There's a shape to AI-assisted development that most teams discover on their own, usually the hard way.
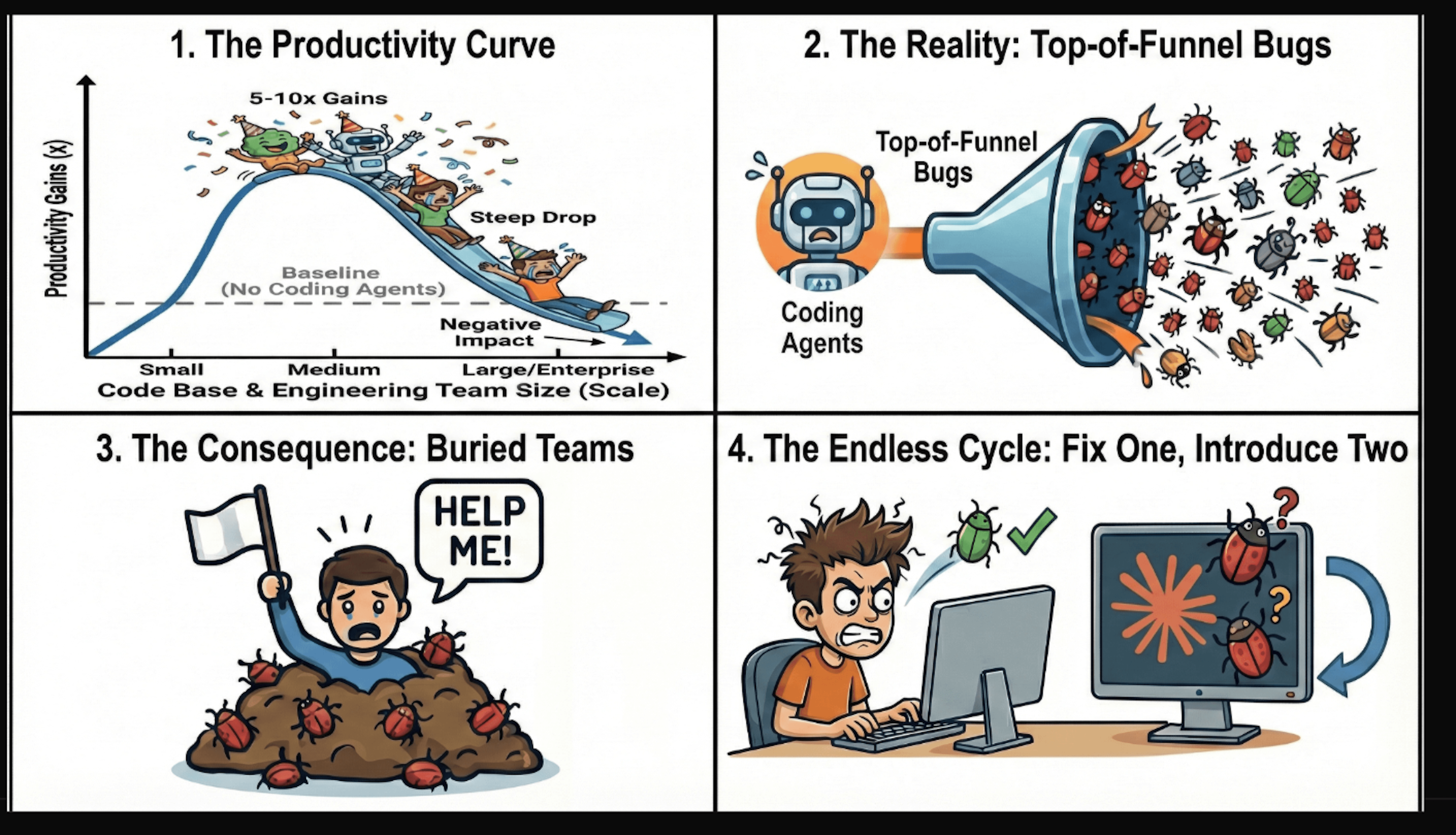
Image generated using Nano Banana Pro
The early months looked great. Features shipped fast, PRs merged clean, the backlog shrank. We were a small team moving like a much bigger one. When an agent introduced something subtly wrong, someone caught it in review or it surfaced fast enough that the fix was obvious. The blast radius of any given mistake was small.
Then the codebase got bigger and neither of those things stayed true.
A PR would land on Monday — clean diff, tests passing, approved in review — and by Thursday something downstream would break in a way that had nothing to do with the diff itself. The change was correct in isolation. It just violated an assumption three services away that nobody had documented.
As a startup, we had advantages: small team, fast iteration cycles. But those same conditions masked the problem. Context lived in people's heads, not in anything the agent could read. Specs were informal. The conventions that kept code consistent were tribal knowledge — obvious to anyone who'd been in the room when the decisions were made, invisible to an agent working from a ticket description.
The volume of output was outpacing the organizational processes meant to catch problems. We weren't shipping faster. We were shipping more — which is a very different thing.
What Broke (And It Wasn't the Agent)
When we traced the failures back to their origins, the agents were doing exactly what we asked. The problem was everything around them.
No feedback loop — Using coding agents naively meant they couldn't bring up services, run tests, spin up a browser, or debug. The agent wrote code, handed it off, and had no way to know if it actually worked. UI code was the worst hit — without a browser, the agent couldn't verify what anything looked like. Without verification, agents took the path of least resistance: if a test failed, delete the test rather than fix the code. If integration was hard, skip the integration step. Giving agents the ability to run tests and check a browser was a necessary first step — but an agent grading its own work has obvious limits. Each uncaught shortcut compounded into technical debt that surfaced later.
Context window as a bottleneck — Finite context is genuinely a model constraint, not a process one. But process determines how badly it hurts you. Even when we used tools that gave agents terminal access, self-verification ate into the context window. Bringing up a server, reading log output, navigating a browser page — all of it was tokens not spent on the actual task. The context would blow past limits even for simple features, and when the agent had to compact and continue, it lost track of decisions it had already made. Each continuation was less effective than the last.
Fragmented tooling & workflows — There was enough delta in how different engineers ran services locally — different aliases, different startup sequences, slightly different environment configs — that even when an agent did try to verify something, the path wasn't consistent. On top of that, different developers had different patterns of using agents — different prompting styles, different levels of context they'd provide — which meant the style and structure of generated code varied across the codebase.
Context in developers' heads — Our codebase had implicit rules: every database query scoped by tenant ID for multi-tenant isolation, certain API patterns preferred in the some services but not others. None of this was written down. It lived in Slack threads and people's heads. The agents filled in the gaps with plausible guesses, and plausible guesses are the hardest bugs to catch because the code reads like it should work. Without guidance to search for existing patterns first, agents defaulted to writing new code — reimplementing utilities and helpers that already existed in the codebase.
All four converged at the same point: code that passed linting, cleared unit tests, got approved in review, and broke something days later. Each late bug felt like a one-off. In aggregate, they were a pattern — and the pattern fed itself. Missing context produced wrong code. No feedback loop caught it before review. It merged. It broke. A developer fixed it manually, learning something that once again stayed in their head. Swapping models wouldn't have changed any of this. The gaps were in the process and tooling around them.
Same Tools, Same Workflow, Different Operator
The problems were in the scaffolding around the agents, not in the agents themselves. So we built that scaffolding.
The goals were straightforward: keep the productivity gains we'd seen early on even as the team and codebase grew, standardize how agents were used across the team so the output was consistent, and get higher quality code through proper verification rather than hope.
Design Goals
Minimal disruption — Engineers already had workflows — Linear for tickets, Notion for specs, GitHub for PRs. Whatever we built had to slide into that flow. If an engineer had to change how they work to accommodate an agent, we'd already failed.
Human-agent interoperability — Not "agent tooling" and "human tooling" as separate tracks, but one set of tools that either operator could use. If a developer starts a service with
cg start server, an agent uses the same command. Same interface, same audit trail. Where agents differ is in having tighter guardrails — sandboxing, restricted network, read-only data — which is precisely what lets them operate with less hand-holding.Maximal safe autonomy — We didn't want to restrict what agents could do. The more autonomy they have, the more useful they are — that's where the productivity gains come from. But autonomy without guardrails is how you end up with an agent that has write access to production. Prompt injection, data exfiltration, credential misuse — agents face these risks regardless of model provider. Every new capability needed a corresponding constraint.
Minimal context gap — Security constraints, multi-tenancy isolation, debugging patterns — most of this lived in Slack threads and people's heads. Reducing the context gap between what developers knew and what agents could access was a prerequisite for everything else.
Reproducible output — Different developers using agents differently meant the same feature could produce structurally different code. Conventions needed to be codified, not assumed — so any agent session would extend existing patterns instead of inventing new ones.

Spec-Driven Workflow
Spec-driven development is not a new idea. Waterfall demanded full upfront specs. Formal methods tried mathematical precision. Design-by-contract embedded specs in code. Model-driven architecture promised generated systems from diagrams. Every version hit the same wall: the cost of writing and maintaining detailed specs exceeded the value they delivered. Specs went stale. Implementation diverged. Developers found it faster to just write the code.
So why does it work now? Because the economics have fundamentally flipped. With agents, a detailed spec is the implementation input. A developer spending thirty minutes writing a clear spec unlocks hours of autonomous agent work. And agents execute specs literally — the same trait that produced plausible-but-wrong code from vague tickets produces correct code from detailed specs. They don't get bored on step seven or creatively reinterpret a requirement. A detailed spec isn't overhead; it's the primary steering mechanism. Without one, agents default to plausible-sounding guesses. The feedback loop matters too: spec to implementation to review now happens in minutes, not the weeks that made waterfall specs rot. It's not "write everything upfront and pray." It's small, focused specs with fast feedback — closer to what agile wanted but couldn't achieve when humans were the bottleneck on both sides of the equation.
Inspired in part by the AgentOS project's approach to extracting and enforcing codebase conventions, what emerged is our version of this. A Linear ticket becomes a Notion spec — the developer refines requirements with the agent and gets team sign-off. The spec becomes a task file — ordered, checkboxed, small enough that each task is a single reviewable unit. The agent picks up the task list and implements it, running tests and verifying as it goes. The output is a PR with artifacts — screenshots, test results, a link back to the spec. Each stage is a checkpoint where the developer can review, redirect, or approve.
The developer's job is deciding what to build. The agent's job is figuring out how. Write a clear spec, break it into pieces, let them execute, review the output. The only difference is the operator.
Agent Toolkit
Unified Tooling
We sandbox coding agents by design — no credentials, restricted network access, restricted filesystem by default. The cg daemon (short for Cogent) is the controlled bridge that makes infrastructure safe to touch. It sits outside the sandbox, owns service processes through a Unix socket, and handles the things agents shouldn't touch directly: rotating IAM tokens, polling health endpoints, proxying read-only queries to database replicas. Any session — or several running in parallel across worktrees — can start, stop, and inspect services through the same daemon. The cg CLI is just the interface; the daemon is what makes it possible for an agent to operate against real infrastructure safely.
Skills
Development follows a pipeline, encoded as skills:
/cgcreatespec— Pulls a Linear ticket and drafts a Notion spec. The developer iterates on it interactively./cgcreatetasks— Breaks the spec into an ordered task list, each item scoped to a single reviewable unit./cgimplement— Works through tasks sequentially, running tests and verifying UI via browser agent at each step./cgcompletespec— Creates the PR with summary, screenshots, test results, and a link back to the spec./cgdevelop— Chains all four end-to-end./cgbugfix— Investigates root cause before writing a fix.Integrations
MCPs (Model Context Protocol servers) and CLI tools give agents structured access to external systems. The agent can:
Authenticate — AWS SSO login, credential management, service account access
Query databases — Read-only replicas via IAM auth, no write access
Track errors — Sentry integration for investigating exceptions and stack traces
Monitor services — Grafana queries for metrics, dashboards, and service health
Inspect infrastructure — Kubernetes pod status, logs, and deployment state
Manage work — Notion for specs and documentation, Linear for issue tracking
Test in-browser — Playwright automation for UI verification, with console inspection and screenshot capture for PR artifacts
Context as Infrastructure
Context is what separates an agent that writes plausible code from one that writes correct code.
CLAUDE.md files organize as a B-tree. The root level covers product mission, tech stack, security rules — context that applies everywhere. Repo-level files add service conventions, build patterns, API styles. Package-level files narrow further to domain models and edge cases. Each layer adds specificity without duplication. An agent working on a specific package inherits everything above it. From that node, the agent searches the codebase and loads task-specific files — the hierarchy seeds context, then the agent digs into specifics.
Task files survive context resets. Long-running features hit compaction — agent summarizes earlier work and continues with compressed context. Our spec-driven workflow produces an ordered, checkboxed task list written to disk. The next session reads the file, finds the first unchecked item, and continues. Works identically when a human takes over mid-feature or work pauses overnight. State lives in a file that any operator can read.
Developer context gathering. Tribal knowledge needs to be searchable. Debugging tips, error messages, and "don't do it that way" explanations get captured in an engineering knowledge base — manually by developers through the CLI, and automatically by agents scraping Slack threads. Both engineers and agents query it with /cgcontext, eliminating the need to interrupt teammates for institutional memory.
Security & Isolation
Every agent session runs in Sandbox Runtime (SRT) — OS-level process isolation via sandbox-exec (macOS) or Bubblewrap (Linux). Filesystem and network access are restricted to what you explicitly allow — nothing more. The cg daemon bridges the gap through a controlled Unix socket, exposing only what the agent needs: service lifecycle commands, AWS auth flows, database queries against read replicas.
Maximal safe autonomy, in practice:
AI SDLC Is a Transition, Not a Switch
Every problem we traced back — the silent regressions, the plausible-but-wrong code, the context that lived in people's heads — had the same root cause: we'd scaled the agent without scaling the system around it. Specs, task files, a daemon, context hierarchies, sandboxing. None of it required a better model.
This post covered local development — where agents spend most of their time and where process gaps compound fastest. CI/CD, staging, production, and incident response each have their own versions of these problems. For most teams, this is a transition, not a switch — one that moves at different speeds depending on team size, domain complexity, and how much tribal knowledge lives in people's heads versus in something an agent can read.
The agent is fine. The process around it is what needs the work.
